1. 前言
红黑树的实现并不困难,但仅根据其定义去理解背后的设计思想却是相当不容易的。
相比较而言,B树是非常直观且容易理解的,了解B树之后,再去看红黑树,就会发现红黑树其实是4阶B树的一种等价实现,红黑树的查找、插入、删除、着色和旋转都可以在4阶B树中一一找到对应关系。
另外,B树及其变体也广泛地运用于数据库系统,譬如 MySQL、MongoDB……等。
这篇文章中,我会先介绍 B树的由来,接着介绍其定义和概念,然后通过图例和流程图来说明相关操作,最后会给出其代码实现。
代码仓库:https://github.com/patricklaux/perfect-code
2. 由来
B 树是由 Rudolf Bayer 和 Edward McCreight 在波音实验室工作期间提出的,论文 “Organization and maintenance of large ordered indices1” 发表于1972年。
B 树是多叉查找树的一种实现,而多叉查找树是二叉查找树的推广。
与内存相比,磁盘具有持久性、大容量和单位存储价格便宜等优点。
但磁盘相对于内存而言是非常缓慢的,二叉树这种内存数据结构并不能很好地应用于磁盘存储。
磁盘读写以页为单位,分页大小为 4KB 时,读取 1B 数据与 4KB 数据均需一次磁盘I/O,耗时几乎相等。
另外,磁盘顺序读写比随机读写的性能要好得多,当读写连续的数据页时,通常都会有不错的性能表现。
因此,根据磁盘数据读写的这些特点,为减少磁盘I/O,很自然的一个想法就是将多个数据项合并存入到一个节点,节点大小恰好是页大小的整数倍。
如下图所示,多个二叉树节点合并成一个节点,这样二叉查找树就变成了多叉查找树 (M-ary search tree)。
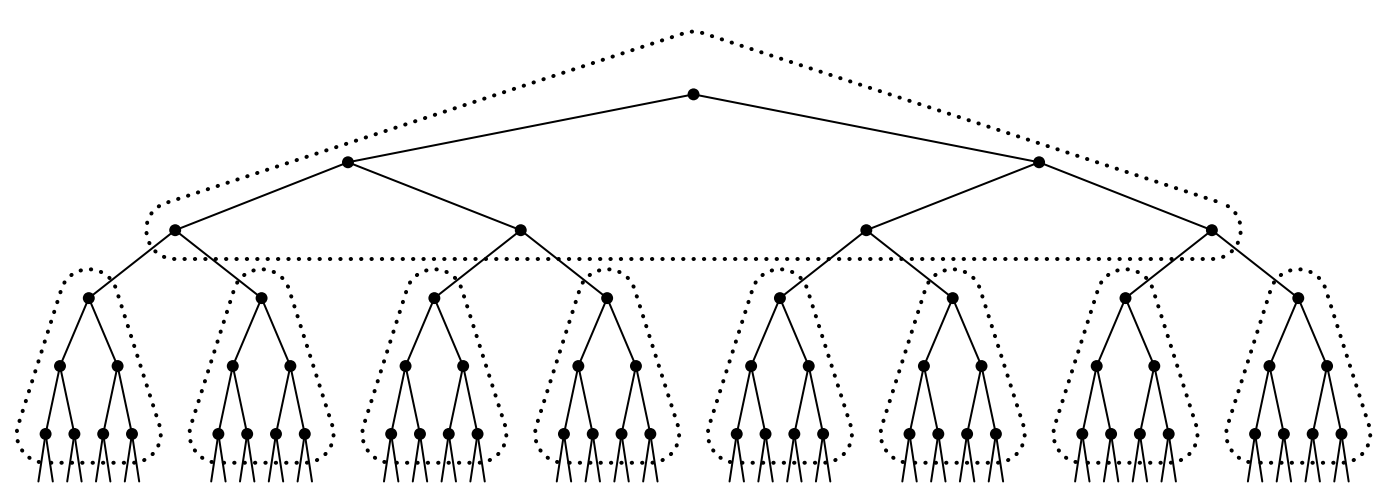
图2.1:节点合并(图片来源于参考资料[2])
一棵完全二叉树 (complete binary tree) 的层数大约为 \( log_2n \),一棵完全多叉树 (complete M-ary tree) 的层数大约为 \( log_mn \),n 为数据记录数。
这意味着,如果有 100万条数据记录,当以二叉树的形式存储到磁盘,搜索一条数据记录约需 20次磁盘I/O: \( log_21000000≈20 \);
如图2.1 所示,通过将 7个节点合并成一个数据页存储到磁盘,变成一棵 8叉搜索树,那么搜索一条数据记录仅需约 7次磁盘I/O:
$$ log_81000000≈7 $$而当将分支因子扩展到 128,那么搜索一条数据记录仅需约 3次磁盘I/O:
$$ log_{128}1000000≈3 $$3. 定义与概念
3.1. 定义
一棵 m 阶 B 树 (B-Tree) 是满足如下性质的多叉查找树:
(1) 每个内部节点至多有 \( m \) 个子节点;
(2) 每个内部节点至少有 \( m/2 \) 个子节点(根除外);
(3) 如根节点为内部节点,其至少有 \( 2 \) 个子节点;
(4) 具有 \( K \) 个子节点的内部节点有 \( K-1 \) 个键;
(5) 所有外部节点的层级均相同,且不携带信息。
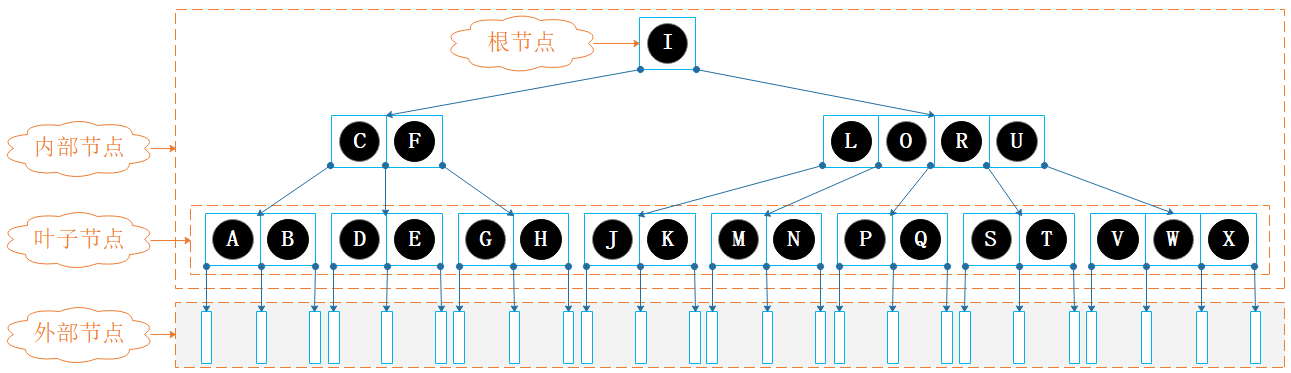
图3.1: 5阶B树
3.2. 概念
叶子节点
叶子节点在原论文中是指包含键的最底层节点(见参考资料1)。
但 Knuth 则认为叶子节点比包含键的最底层节点再低一级,叶子节点即外部节点(见参考资料2)。
这里采用原论文中的描述,叶子节点与外部节点并非同一概念。
外部节点
外部节点指的是不在树中的节点,其可能是空指针,也可能指向其它数据文件等。
由于 B 树中外部节点不携带信息,因此通常用空指针或一个特殊的空节点来指代。
但在 B 树的变体 B+ 树中,外部节点存储了键关联的数据信息,是有实际用途的。
提示:由于B树 的外部节点无实际用途,后续图示将省略外部节点。
内部节点
很多文献都可以看到“内部节点”这个名词,但都没有给出严格定义,所以经常有不同的理解。
我倾向于认为内部节点与外部节点是相互对应的概念,如果一个节点不是外部节点,那么其就是内部节点。
为避免歧义,这里先下一个定义:B 树中所有包含键的节点均为内部节点。
阶(order)
一个节点可能包含的最大子节点数,即 B树定义中的 m。
图3.1 是一棵 5阶B树,根据定义 1 和 2,根以外的内部节点至少有 \( ⌈m/2⌉=⌈5/2⌉=3 \) 个子节点,且至多有 \( m=5 \) 个子节点,因此 5阶 B树又称为 (3, 5) 树。
同理,3阶B树又称为 (2, 3) 树(或 2-3 树),4阶B树又称为 (2, 4) 树(或 2-3-4 树),6阶B树又称为 (3, 6) 树,7阶B树又称为 (4, 7) 树……
定义2 是为了避免 B 树简单地退化成二叉树。
注:\( m/2 \) 的计算是向上取整,如 \( 3/2=1.5 \),向上取整后为 2;\( 5/2=2.5 \)$,向上取整后为 3。
键
这里用 k 来表示每个内部节点包含的键的数量。
根据定义 4,根节点具有 [2, m] 个子节点,那么其可能包含的键数量: \( 1 \leqslant k \leqslant m-1 \);
根节点以外的内部节点具有 [m/2, m] 个子节点,那么其可能包含的键数量:\( m/2-1 \leqslant k \leqslant m-1 \);
如图3.1 所示的 5 阶 B 树,根节点可能包含 1 至 4 个键,其它内部节点可能包含 2 至 4 个键。
信息
信息指的是键关联的值,又或是键关联的数据在文件的索引地址等。
B 树中并不关心信息为何种形式,这取决于具体的实现。
根节点
当 B 树为空树时,根节点用空指针或一个特殊的空节点来指代,这时根节点是外部节点;其它情况下根节点是内部节点。
高度
当 B 树为空树时,其高度为 0。
如图3.1 所示的 5 阶B树,如果计算高度时包含外部节点,则为 4;如计算高度时不包含外部节点,则为 3。
注:关于高度,部分资料的定义是包含外部节点,部分资料的定义则不包含外部节点。
4. 实现
4.1. 节点定义
class Node<K, V> {
//节点当前包含的键数量
int size;
// 父节点
Node<K, V> parent;
// 数据项数组(每一个数据项是一个键值对,根据键升序排列)
Pair<K, V>[] items;
// 子节点数组(根据键升序排列)
Node<K, V>[] children;
Node(int order) {
this.items = new Pair[order - 1];
this.children = new Node[order];
}
Node(int order, Pair<K, V> item) {
this.items = new Pair[order - 1];
this.children = new Node[order];
this.items[size++] = item;
}
}
有序性
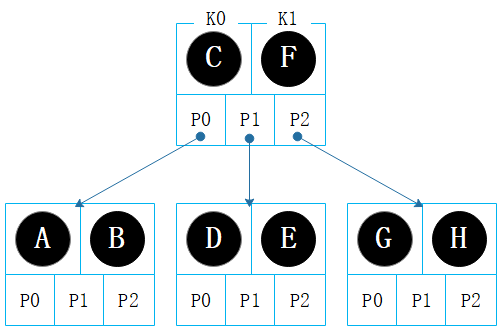
图4.1:节点示意
观察图4.1,我们可以发现:
一个节点中,键是升序存储的,譬如 C < F。
一个节点中,其子节点也是升序存储的,譬如 【A B】< 【D E】< 【G H】。
对于任意一个内部节点,K 表示键集合,P 表示子节点集合,那么有:
$$ P_0 \lt K_0 \lt P_1 \lt K_1 \lt P_2 \lt K_2 \lt … \lt P_{n} \lt K_n \lt P_{n+1} $$如图4.1 所示:【A B】< C < 【D E】< F < 【G H】
如果用二叉查找树来类比,那么 \( P_0 \) 是 \( K_0 \) 的左孩子; \( P_1 \) 既是 \( K_0 \) 的右孩子,也是 \( K_1 \) 的左孩子; \( P_2 \) 是 \( K_1 \) 的右孩子。
特别说明
为避免实现过于复杂,这里省略从外存读取数据文件并转换为主存节点的过程,直接在主存中读写子节点。
如果是从外存读取数据文件,子节点数组保存的应该是子节点在数据文件中的索引地址,类似于如下定义:
// 子节点索引数组
long[] children;
// 根据索引从数据文件读取数据并转换为节点
Node<K, V> readFromSecondary(File dataFile, long position);
// 主存中的节点修改后根据索引写入数据文件
boolean writeToSecondary(Node<K,V> p, File dataFile, long position);
4.2. 查找
依惯例,先从最简单的查找开始。
4.2.1. 查找流程
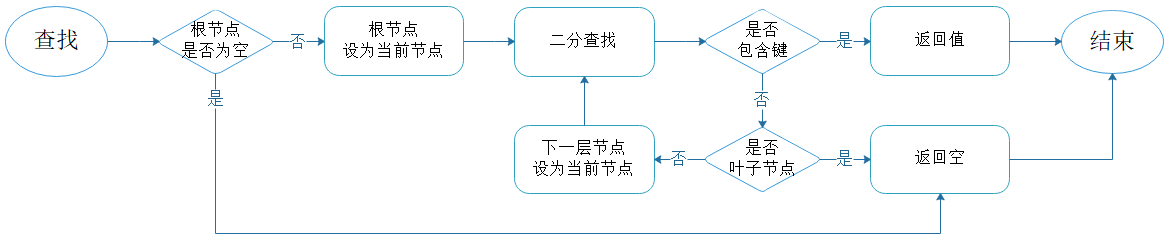
图4.2:查找流程
4.2.2. 代码实现
@Override
public V get(K key) {
Assert.notNull(key);
if (root == null) {
return null;
}
// 1.先根据 Key 找到包含该 Key 的节点
Tuple2<Integer, Node<K, V>> tuple2 = search(key);
int pos = tuple2.getT1();
Node<K, V> x = tuple2.getT2();
Pair<K, V> item = x.items[pos];
// 2.如果 pos 对应的数据项不为空且两个键相同,返回值;否则返回空
if (item != null && compare(item.getKey(), key) == 0) {
return item.getValue();
}
return null;
}
/**
* 查找键所在的节点 及 键在该节点的索引位置
*
* @param key 键
* @return 返回二元组:(索引位置, 节点)
*/
private Tuple2<Integer, Node<K, V>> search(K key) {
Node<K, V> p = root;
while (true) {
// 1. 二分查找(m 为中值,upper 为上界,lower 为下界)
int m = p.size / 2, upper = p.size, lower = 0;
while (m >= lower && m < upper) {
int cmp = compare(p.items[m].getKey(), key);
if (cmp > 0) {
upper = m;
m = m - Math.round((float) (m - lower) / 2);
} else if (cmp < 0) {
lower = m;
m = m + Math.round((float) (upper - m) / 2);
} else {
// 1.1.节点包含该键
return Tuples.of(m, p);
}
}
// 1.2.节点不包含该键
// 1.2.1.已到达叶子节点,结束查找
if (p.isLeaf()) {
return Tuples.of(m, p);
}
// 1.2.2.未到达叶子节点,查找子节点
p = p.children[m];
}
}
4.2.3. 性能分析
B树查找过程是从根节点开始逐层向下查找(节点内部执行二分查找),如果一直未命中,递归查找过程会直到叶子节点为止。
因此,最坏情况下 B树的查找时间复杂度为:
$$C_{max}=h(log_2m)$$对于B树来说,节点内部的二分查找在主存中进行,因此时间消耗非常少,所以我们更关心耗时的外存访问次数,也就是 h 的取值范围。
那么,我们这就来求高度 h 的上界和下界。
设 N 为 B树中的数据项数量,高度为 h,阶为 m。
假设高度 h 一定,当树中所有节点包含的数据项数量均为最大值,此时树中的数据项数量最多。
第0层:\( L_0=(m-1)m^0 \)
第1层:\( L_1=(m-1)m^1 \)
第2层:\( L_2=(m-1)m^2 \)
第3层:\( L_3=(m-1)m^3 \)
……
第h层:\( L_h=(m-1)m^h \)
所有层求和,可得树中的数据项的最大数量:
(式4.1) :\( N_{max}=(m-1)\sum_{k=0}^{h}m^k=(m-1)\frac{(m^h-1)}{m-1}=m^h-1 \) (h ≥ 1)
假设高度 h 一定,当树中所有节点包含的数据项数量均为最小值,此时树中的数据项数量最少。
第0层:\( L_0=1 \)
第1层:\( L_1=2(⌈m/2⌉-1)(⌈m/2⌉)^0 \)
第2层:\( L_2=2(⌈m/2⌉-1)(⌈m/2⌉)^1 \)
第3层:\( L_3=2(⌈m/2⌉-1)(⌈m/2⌉)^2 \)
……
第h层: \( L_h=2(⌈m/2⌉-1)(⌈m/2⌉)^{h-1} \)
所有层求和,可得树中的数据项的最小数量:
(式4.2): \( N_{min}=1+2(⌈m/2⌉-1)\frac{{⌈m/2⌉}^{h-1}-1}{⌈m/2⌉-1}=2(⌈m/2⌉^{h-1})-1 \) (h ≥ 1)
当B树中的数据项数量N一定时,每个节点包含的键数量最多时 h 最小,因此由式4.1 可得高度 h 的最小值:
(式4.3): \( h_{min}=log_m(N+1) \) (h ≥ 1)
当B树中的数据项数量N一定时,每个节点包含的键数量最少时 h 最大,因此由式4.2 可得高度 h 的最大值:
(式4.4): \( h_{max}=log_{⌈m/2⌉}(\frac{N+1}{2})+1 \) (h ≥ 1)
综合式4.3 和式 4.4,可得出高度 h 的上界和下界:
(式4.5): \( log_m(N+1) \leqslant h \leqslant log_{⌈m/2⌉}(\frac{N+1}{2})+1 \) (h ≥ 1)
4.3. 插入
4.3.1. 插入流程
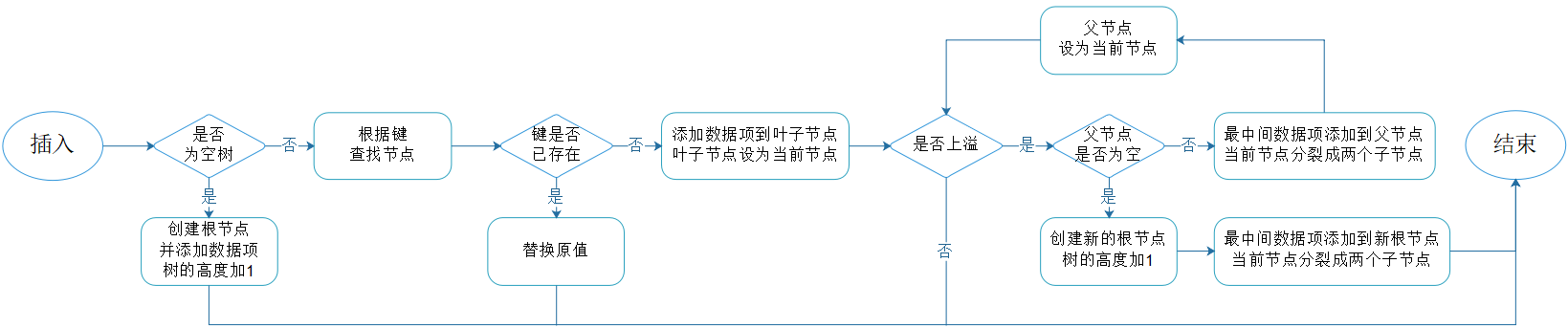
图4.3:插入流程
插入新数据项,需先执行查找:如果命中则替换原数据项;如果未命中,则找到相应的叶子节点。
当将新数据项存入到节点,可能会导致节点包含的数据项数量超过允许的最大值,因此需要通过分裂来解决上溢问题。
插入操作稍稍有些复杂,我们先看看下面的插入示例。
4.3.2. 插入示例
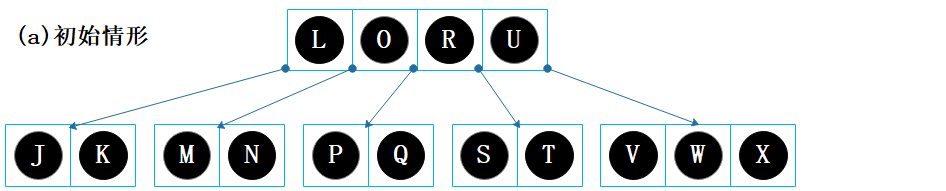
这是一棵 5阶B树,因此一个内部节点最多会有 4个键和 5个子节点。
接下来,会演示插入 Y 和 Z,看看是如何通过分裂来解决上溢问题。
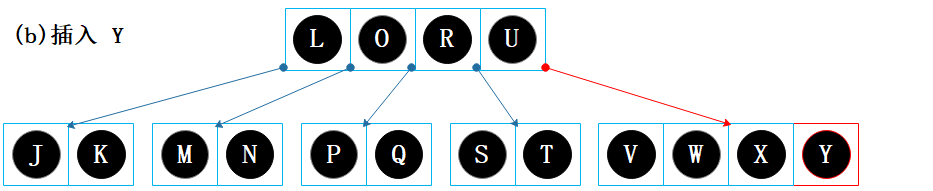
对节点【L O R U】进行二分查找,该节点无 Y 键且非叶子节点,Y 比 U大,进入下一层:U的右孩子;
对节点【V W X】进行二分查找,该节点无 Y 键且是叶子节点,Y 比 X 大,Y 保存到 X 的右侧;
节点【V W X Y】包含的数据项未超过最大值4,结束。

对节点【L O R U】进行二分查找,该节点无 Z 键且非叶子节点,Z 比 U大,进入下一层:U的右孩子;
对节点【V W X Y】进行二分查找,该节点无 Z 键且是叶子节点,Z 比 Y 大,Z 保存到 Y 的右侧;
节点【V W X Y Z】包含的数据项超过最大值4,需处理上溢问题。
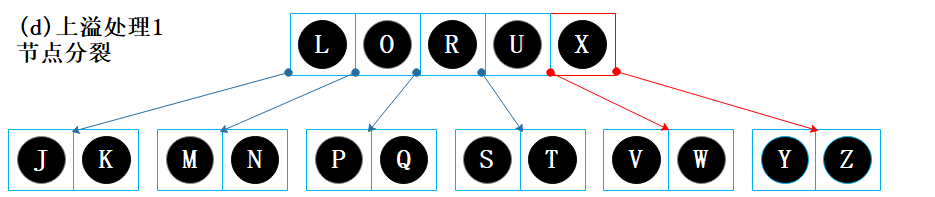
提取节点【V W X Y Z】的最中间数据项 X 保存到父节点【L O R U】;
以 X 为界将其它数据项分裂成两个子节点【V W】和【Y Z】;
节点【L O R U X】包含的数据项超过最大值4,需处理上溢问题。
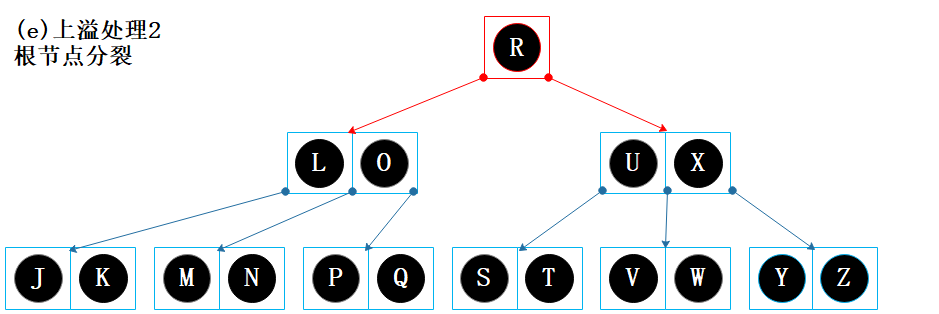
节点【L O R U X】为根节点,提取节点【L O R U X】的最中间数据项 R 作为新的根节点,树的高度+1;
以 R 为界将其它数据项分裂成两个子节点【L O】和【U X】,结束。
小结
观察上面的例子,我们可以发现对于上溢问题:可能需要递归向上分裂,直到根节点才结束3。
4.3.3. 代码实现
@Override
public void put(K key, V value) {
Assert.notNull(key);
Assert.notNull(value);
// 1.如果为空树,创建根节点并添加键值对
if (root == null) {
root = new Node<>(maxOrder, Pairs.of(key, value));
size.increment();
height.increment();
return;
}
// 2.查找键,并判断键是否已存在
Tuple2<Integer, Node<K, V>> tuple2 = search(key);
int pos = tuple2.getT1();
Node<K, V> x = tuple2.getT2();
Pair<K, V> item = x.items[pos];
if (item != null && compare(item.getKey(), key) == 0) {
// 2.1. 当前节点已存在该 Key
x.setItem(pos, Pairs.of(key, value));
return;
}
// 2.2. 键不在树中,增加树的size
size.increment();
// 3.添加键值对到最底层的内部节点
x.addItem(pos, Pairs.of(key, value));
// 4. 上溢处理
solveOverflow(x);
}
4.3.4. 上溢与分裂
private void solveOverflow(Node<K, V> x) {
// 判断当前节点是否上溢(键数量超过允许的最大值)
while (x.size > maxElement) {
Node<K, V> p = x.parent;
// 1.如果出现上溢,提取当前节点最中间的数据项
Pair<K, V> item = x.items[median];
int pos = 0;
if (p == null) {
// 2.父节点为空,说明当前节点为 root,创建新的根节点
root = p = new Node<>(maxOrder);
// 2.1.树高 +1
height.increment();
} else {
// 3.获取中间数据项在父节点中的插入位置
pos = position(p, x);
}
// 4.当前节点最中间的数据项并添加到父节点
p.addItem(pos, item);
// 5.当前节点分裂成两个子节点并添加到父节点
split(p, x, pos);
// 6.父节点设为当前节点
x = p;
}
}
/**
* 上溢节点分裂为两个节点
*
* @param p 父节点
* @param x 上溢节点
* @param pos 索引位置
*/
private void split(Node<K, V> p, Node<K, V> x, int pos) {
Node<K, V> lc = new Node<K, V>(maxOrder).setItems(x, 0, median);
Node<K, V> rc = new Node<K, V>(maxOrder).setItems(x, median + 1, maxElement - median);
p.setChild(pos, lc);
p.addChild(pos + 1, rc);
}
4.4. 删除
4.4.1. 删除流程
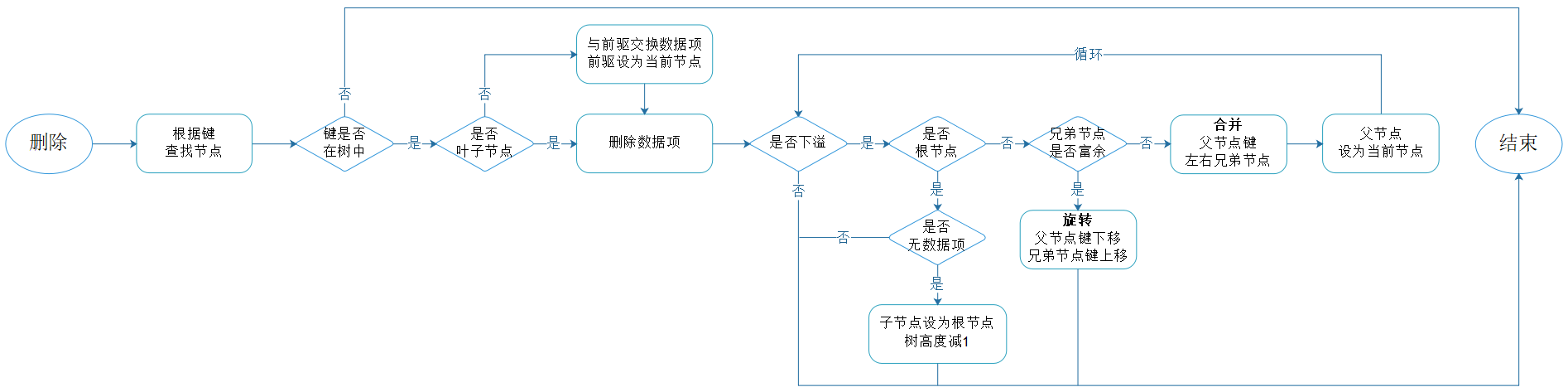
图4.4:删除流程
删除数据项,如果待删除的数据项所在的节点非叶子节点,需要与其前驱交换数据项,然后再从叶子节点开始执行删除。
当将数据项删除之后,可能会导致节点包含的数据项数量小于允许的最小值,因此需要通过旋转和合并来解决下溢问题。
还是一样,我们先看看具体的删除示例。
4.4.2. 删除示例
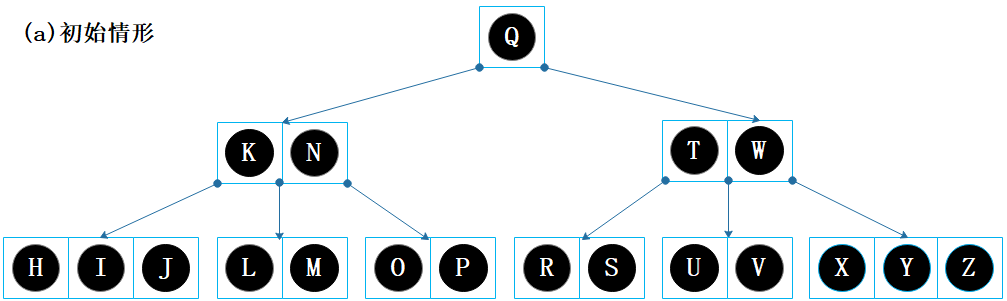
这是一棵 5阶B树,因此根节点至少有1个键和2个子节点,其它内部节点至少会有 2个键和 3个子节点。
接下来,会演示删除 K, V 和 Y,看看是如何通过旋转和合并解决下溢问题。
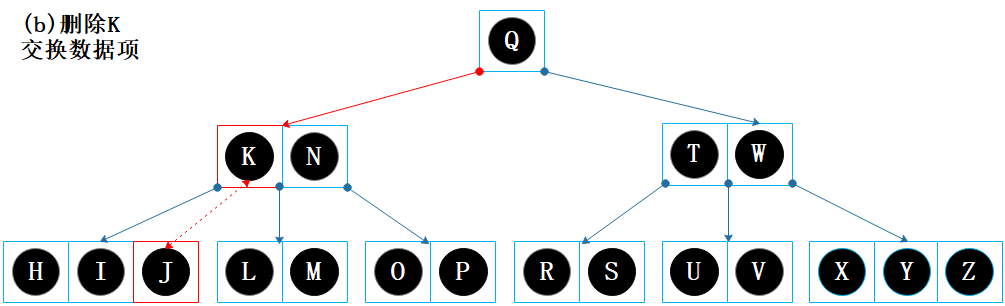
根据键 K 找到节点【K N】,该节点非叶子节点,找到 K 的前驱 J。
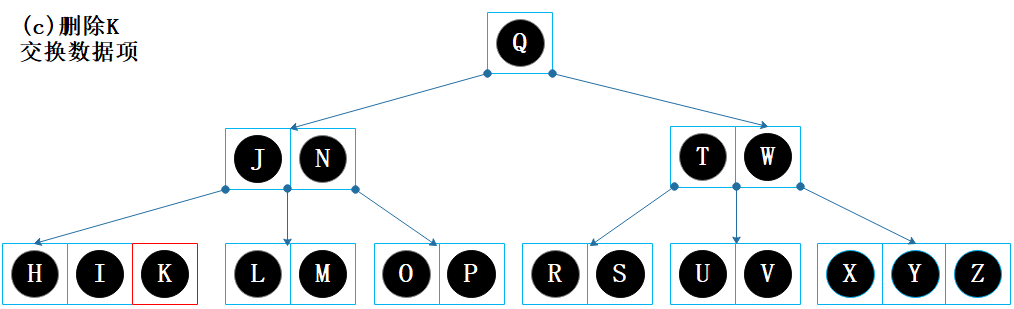
K 和 J 交换。
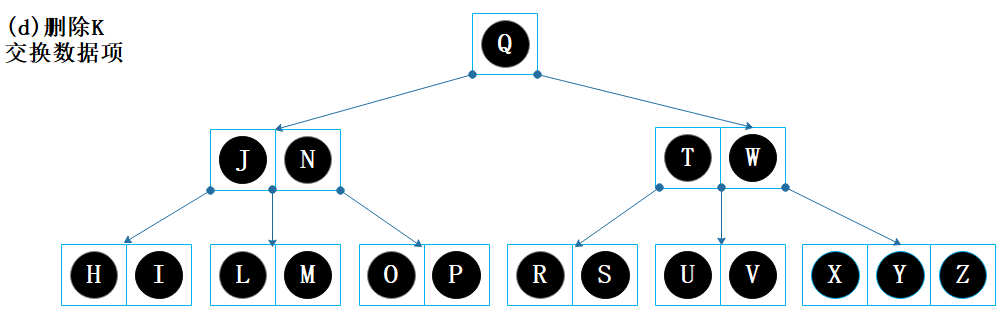
删除 K;
节点【H I】的剩余数据项数量为 2,没有下溢问题,结束。
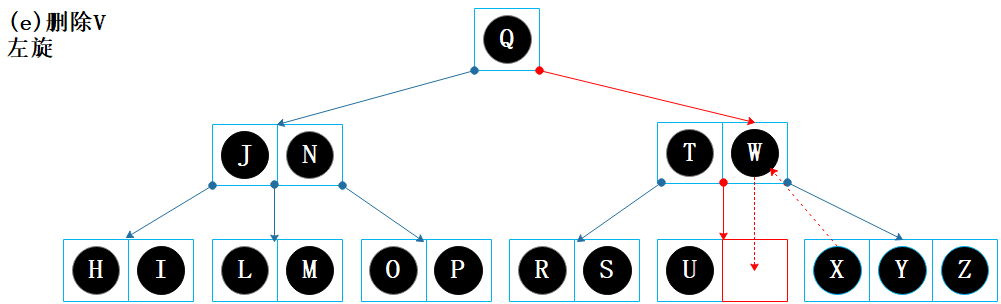
根据键 V 找到节点【U V】,该节点为叶子节点,无需交换,直接删除 V。
删除 V 后节点【U】的数据项数量少于2,出现下溢问题;
节点【U】的左兄弟没有富余节点,右兄弟有富余节点,因此通过左旋来解决下溢问题;
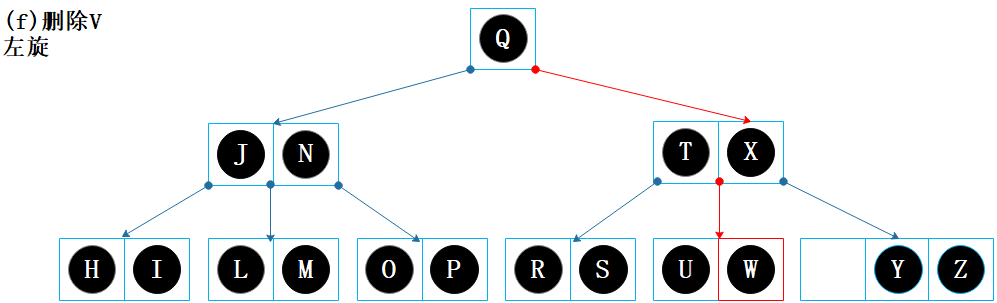
父节点的 W 移入【U】节点,当前节点变成【U W】,父节点的变成【T】;
右兄弟节点的 X 移入父节点;父节点的变成【T X】,右兄弟节点变成【Y Z】。
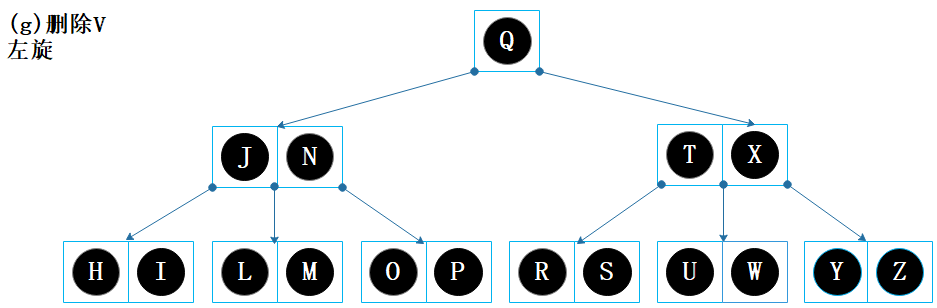
旋转完成后如上图,结束。
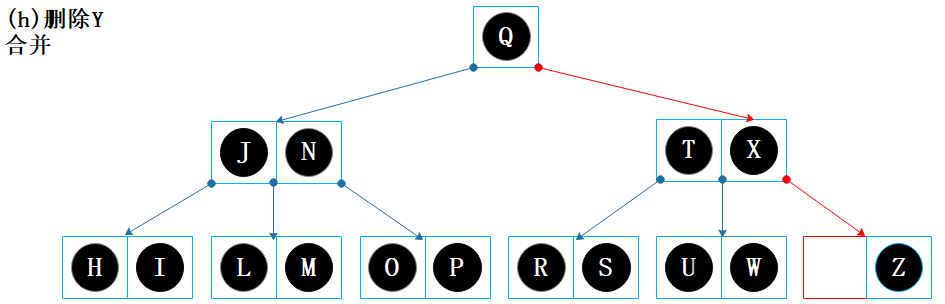
根据键 Y 找到节点【Y Z】,该节点为叶子节点,直接删除 Y; 删除 Y 后节点【Z】仅余 1 个键,出现下溢问题; 节点【Z】的左兄弟和右兄弟均没有富余节点,因此需要通过合并来解决下溢问题。
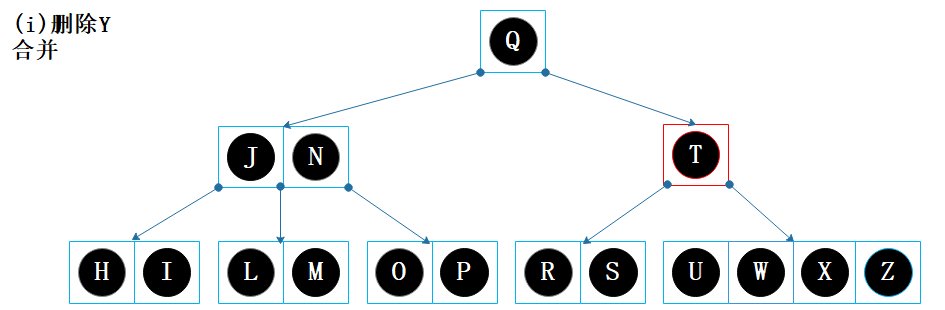
父节点【T X】的键 X 下移 ,并与节点【U W】和节点【Z】合并,合并后变成【U W X Z】。 父节点变成【T】,仅余一个键,再次出现下溢问题; 节点【T】的兄弟节点没有富余,因此需要通过合并来解决下溢问题。
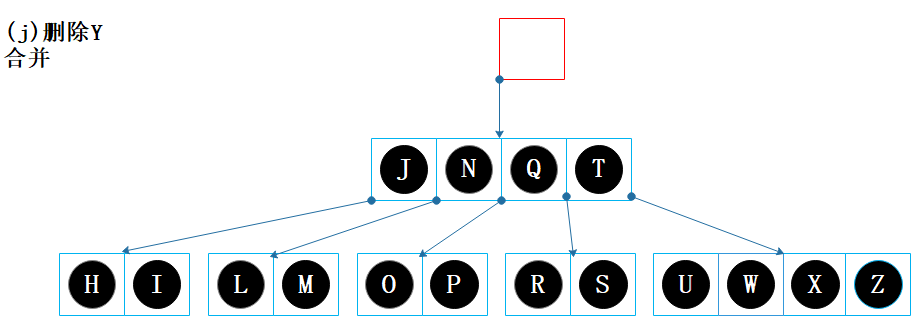
父节点【Q】的键 Q 下移,并与节点【T】和节点【J N】合并,合并后变成【J N Q T】; 父节点【】已经没有键,且其为根节点。
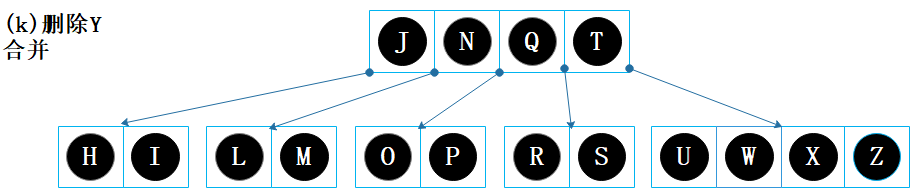
移除父节点【】,节点【J N Q T】设为根节点,树的高度减 1,结束。
小结
观察上面的例子,我们可以发现对于下溢问题:
如果兄弟节点有富余,那么一次旋转操作即可结束;
如果兄弟节点无富余,合并操作可能导致父节点再次出现下溢,最坏情况下需要递归执行到根节点才结束3。
4.4.3. 代码实现
@Override
public V remove(K key) {
Assert.notNull(key);
// 1.查找键所在节点
Tuple2<Integer, Node<K, V>> tuple2 = search(key);
int pos = tuple2.getT1();
Node<K, V> x = tuple2.getT2();
Pair<K, V> item = x.items[pos];
// 2.如果键不存在于树中,结束
if (item == null || compare(item.getKey(), key) != 0) {
return null;
}
// 3.如果键存在于树中,删除数据项,树包含的数据项数量减1
size.decrement();
V oldVal = item.getValue();
if (x.isLeaf()) {
// 3.1.如果是叶子节点,直接删除
x.deleteItem(pos);
} else {
// 3.2.如果是非叶节点,与前驱交换数据项,前驱必定为叶子节点
x = predecessor(x, pos);
}
// 4.解决下溢问题
solveUnderflow(x);
// 5.返回旧值
return oldVal;
}
/**
* 与前驱交换数据项
*
* @param x 待删除键的节点
* @param pos 键的索引位置
* @return 前驱节点
*/
private Node<K, V> predecessor(Node<K, V> x, int pos) {
Node<K, V> pred = x.children[pos];
while (!pred.isLeaf()) {
pred = pred.children[pred.size];
}
// 1.前驱节点中的最后一个数据项即为前驱
int swapIndex = pred.size - 1;
x.items[pos] = pred.items[swapIndex];
// 2.前驱节点删除已交换的数据项
pred.deleteItem(swapIndex);
// 3.返回前驱节点
return pred;
}
4.4.4.下溢与合并
/**
* 下溢处理
*
* @param x 当前节点
*/
private void solveUnderflow(Node<K, V> x) {
while (x.size < median) {
Node<K, V> p = x.parent;
if (p == null) {
// 1.当前节点为根节点,且已无数据项,其唯一子节点设为根节点
if (x.size == 0) {
root = x.children[0];
height.decrement();
}
return;
}
int pos = position(p, x);
// 2. 旋转
if (pos > 0) {
Node<K, V> sl = p.children[pos - 1];
// 2.1.左兄弟有富余数据项,右旋
if (sl.size > median) {
rotateRight(p, x, sl, pos);
return;
}
}
if (pos < p.size) {
Node<K, V> sr = p.children[pos + 1];
// 2.2.右兄弟有富余数据项,左旋
if (sr.size > median) {
rotateLeft(p, x, sr, pos);
return;
}
}
// 3. 合并
if (pos > 0) {
merge(p, p.children[pos - 1], x, pos - 1);
} else {
merge(p, x, p.children[pos + 1], pos);
}
x = p;
}
}
/**
* 获取子节点在父节点中的索引位置
*
* @param p 父节点
* @param x 子节点
* @return 索引位置
*/
private int position(Node<K, V> p, Node<K, V> x) {
for (int i = 0; i <= p.size; i++) {
if (x == p.children[i]) {
return i;
}
}
return -1;
}
/**
* 右旋
*
* @param p 父节点
* @param x 当前节点
* @param sl 当前节点的左兄弟
* @param pos 父节点中用于旋转的数据项索引位置
*/
void rotateRight(Node<K, V> p, Node<K, V> x, Node<K, V> sl, int pos) {
x.addItem(0, p.items[pos]);
p.setItem(pos, sl.items[sl.size - 1]);
sl.deleteItem(sl.size - 1);
x.addChild(0, sl.children[sl.size]);
sl.deleteChild(sl.size);
}
/**
* 左旋
*
* @param p 父节点
* @param x 当前节点
* @param sr 当前节点的右兄弟
* @param pos 父节点中用于旋转的数据项索引位置
*/
void rotateLeft(Node<K, V> p, Node<K, V> x, Node<K, V> sr, int pos) {
x.addItem(x.size, p.items[pos]);
p.setItem(pos, sr.items[0]);
sr.deleteItem(0);
x.addChild(x.size, sr.children[0]);
sr.deleteChild(0);
}
/**
* 合并兄弟节点
*
* @param p 父节点
* @param l 左孩子节点
* @param r 右孩子节点
* @param pos 父节点中用于合并的数据项索引位置
*/
void merge(Node<K, V> p, Node<K, V> l, Node<K, V> r, int pos) {
l.addItem(l.size, p.items[pos]);
p.deleteItem(pos);
p.deleteChild(pos + 1);
l.merge(r);
}
5. 小结
这篇文章介绍了 B 树的基本操作,实现其实并不复杂,全部代码也就是400行,完整代码在这里:BTree。
如果有兴趣的话,加上锁和读写数据文件的相关代码,其实就可以看作是一个极简的数据库了。
当然,要实现一个真正可用的数据库,还需要考虑锁、事务、缓存、写日志、数据文件、网络协议、SQL 解析等,这就不那么容易了。
下一篇文章,我将会结合 4 阶 B 树来介绍红黑树的设计和操作,欢迎继续关注。